Create a Custom Source for AWS CodePipeline - How to Use Azure DevOps Repos with AWS Pipelines - Part 1
Recently a very interesting blog post on the AWS DevOps blog was published which goes into much detail
how to use third-party Git repositories as source for your AWS CodePipelines.
Unfortunately, this article came too late for our own integration of Azure DevOps Repos into our AWS CI/CD Pipelines and we had to find our own solution when we started to move our code Repos to Azure DevOps earlier this year.
I’m happy to share some more details how we succeeded with this integration using a custom source for AWS CodePipeline.
In this Part 1 of the blog posts I will show you all details of the solution and in a Part 2 I plan to describe every step which is needed to deploy such a solution.
Solution Overview
Big parts of the solution are equal to the architecture described in the Blog post by Kirankumar but there are some small but important differences.
Let’s look at the architecture of our solution:
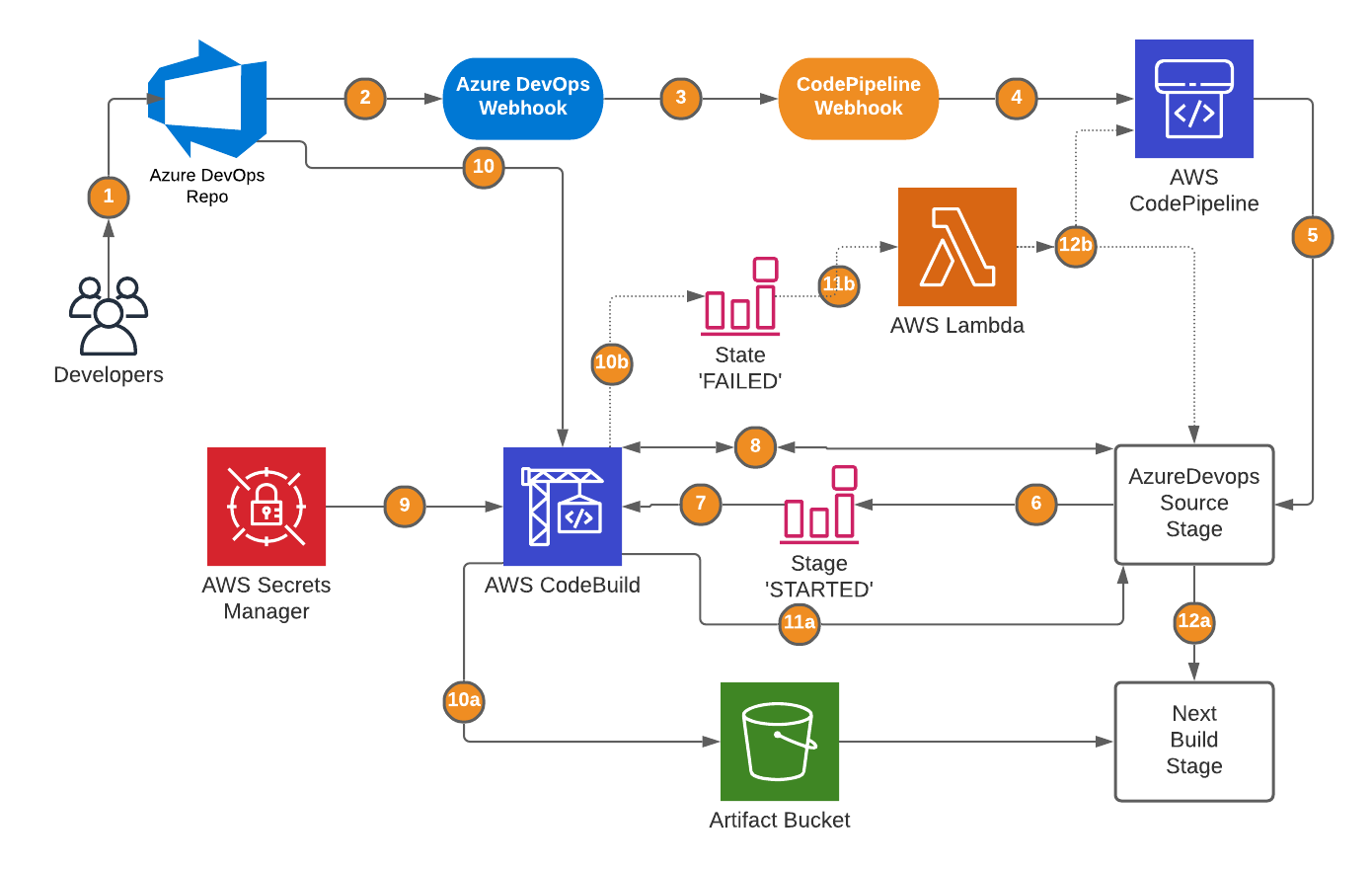
Let’s go through all the steps:
-
A developer commits a code change to the Azure DevOps Repo
-
The commit triggers an Azure DevOps webhook
-
The Azure DevOps webhook calls a CodePipeline webhook
-
The webhook starts the CodePipeline
-
The CodePipeline puts the first stage into 'Progress' and starts the source stage
-
A CloudWatch Event Rule is triggered by the stage change to 'STARTED'
-
The event rule triggers AWS CodeBuild and submits the pipeline name
-
AWS CodeBuild polls the source stage job details and acknowledges the job
-
The SSH key is received by CodeBuild from the AWS Secrets Manager
a) Successful builds
-
a) CodeBuild uploads the zipped artifact to the S3 artifact bucket
-
a) CodeBuild puts the source stage into 'Succeeded'
-
a) CodePipeline executes the next stage
b) Failed builds
-
b) A CloudWatch Event Rule is triggered by the state change to 'FAILED'
-
b) The event rule triggers a Lambda function and provides pipeline execution/job details
-
b) Depending where the CodeBuild process failed the source stage is put into 'Failed' or the pipeline execution is stopped/abandoned
As you can see the solution is very similar, but we omit a long running Lambda function and put all the logic into CodeBuild. We only need a short running Lambda function for error handling. Whenever CodeBuild fails we interconnect this Lambda function and CodeBuild through a CloudWatch Event Rule.
But let’s do a deep dive into the different parts of the solution.
Again, you will find the complete example in my AWS_Cloudformation_Examples Github Repo.
Webhooks
This part of the solution is pretty straightforward and almost the same configuration for all the different third-party Git repository providers.
You will find the CloudFormation code for the CodePipeline webhook in AzureDevopsPipeline.yaml.
Let’s look at the Azure DevOps specific parts of the webhook:
120 Webhook:
121 Type: 'AWS::CodePipeline::Webhook'
122 Properties:
123 AuthenticationConfiguration: {}
124 Filters:
125 - JsonPath: "$.resource.refUpdates..name"
126 MatchEquals: !Sub 'refs/heads/${Branch}'
127 Authentication: UNAUTHENTICATED
128 TargetPipeline: !Ref AppPipeline
129 TargetAction: Source
130 Name: !Sub AzureDevopsHook-${AWS::StackName}
131 TargetPipelineVersion: !Sub ${AppPipeline.Version}
132 RegisterWithThirdParty: FalseIf we look at line 125 we see the JSON Path which will be used to find the branch of the Repo which triggered the Azure DevOps branch. For most third-party Git repositories this path equals to
'$.ref'
but the structure of the request generated by the Azure DevOps Webhook looks different and we will find the branch using
'$.resource.refUpdates..name'
as JSON path.
Almost every third-party Git repository provider gives you access to the history of webhook executions and you will find the complete requests there. So, whenever you try to integrate a third-party provider look at the webhook requests first and define the correct JSON path for your branch filter.
This filter will now be used to decide if the branch which triggered the AzureDevops Webhook is the one we are using in our Source Stage definition of our pipeline and will trigger the CodePipeline execution (step 4).
CodePipeline CustomActionType
The CustomActionType for the CodePipeline Source Stage will be created by the AzureDevopsPreReqs.yaml CloudFormation template:
11 AzureDevopsActionType:
12 Type: AWS::CodePipeline::CustomActionType
13 Properties:
14 Category: Source
15 Provider: "AzureDevOpsRepo"
16 Version: "1"
17 ConfigurationProperties:
18 -
19 Description: "The name of the MS Azure DevOps Organization"
20 Key: false
21 Name: Organization
22 Queryable: false
23 Required: true
24 Secret: false
25 Type: String
26 -
27 Description: "The name of the repository"
28 Key: true
29 Name: Repo
30 Queryable: false
31 Required: true
32 Secret: false
33 Type: String
34 -
35 Description: "The name of the project"
36 Key: false
37 Name: Project
38 Queryable: false
39 Required: true
40 Secret: false
41 Type: String
42 -
43 Description: "The tracked branch"
44 Key: false
45 Name: Branch
46 Queryable: false
47 Required: true
48 Secret: false
49 Type: String
50 -
51 Description: "The name of the CodePipeline"
52 Key: false
53 Name: PipelineName
54 Queryable: true
55 Required: true
56 Secret: false
57 Type: String
58 InputArtifactDetails:
59 MaximumCount: 0
60 MinimumCount: 0
61 OutputArtifactDetails:
62 MaximumCount: 1
63 MinimumCount: 1
64 Settings:
65 EntityUrlTemplate: "https://dev.azure.com/{Config:Organization}/{Config:Project}/_git/{Config:Repo}?version=GB{Config:Branch}"
66 ExecutionUrlTemplate: "https://dev.azure.com/{Config:Organization}/{Config:Project}/_git/{Config:Repo}?version=GB{Config:Branch}"Large parts of the code are self-explanatory.
We need the Azure DevOps
Organization, Project, Reponame and Branch
to git clone the required repo branch.
All these properties are must fields and as you can see are sufficient to create a back link to the Project in Azure DevOps as seen on line 65.
The property
PipelineName
isn’t needed to get the Git repo but will be used to identify the correct CodePipeline job which should be processed. Therefore, this property has to be query able, otherwise you will get an error later on when using the query-param parameter on line 148 (had to find out this the hard way).
CloudWatch Events Rules
This part is found in the AzureDevopsPreReqs.yaml CloudFormation template as well:
210 CloudWatchEventRule:
211 Type: AWS::Events::Rule
212 Properties:
213 EventPattern:
214 source:
215 - aws.codepipeline
216 detail-type:
217 - 'CodePipeline Action Execution State Change'
218 detail:
219 state:
220 - STARTED
221 type:
222 provider:
223 - AzureDevOpsRepo
224 Targets:
225 -
226 Arn: !Sub ${BuildProject.Arn}
227 Id: triggerjobworker
228 RoleArn: !Sub ${CloudWatchEventRole.Arn}
229 InputTransformer:
230 InputPathsMap: {"executionid":"$.detail.execution-id", "pipelinename":"$.detail.pipeline"}
231 InputTemplate: "{\"environmentVariablesOverride\": [{\"name\": \"executionid\", \"type\": \"PLAINTEXT\", \"value\": <executionid>},{\"name\": \"pipelinename\", \"type\": \"PLAINTEXT\", \"value\": <executionid>}]}"I only want to draw your attention to lines 125-126 where the event input will be transformed to an output which later will be used by CodeBuild (step 7).
We will hand over two CodeBuild environment variables,
executionid
and
pipelinename
. Creating the InputTemplate was challenging, as you can see you have to carefully escape all double quotes and you have to override the CodeBuild environment variables.
Fortunately the API Reference Guide for AWS CodeBuild is very well documented and you find the needed request syntax there → use environmentVariablesOverride and provide an array of EnvironmentVariable objects, in this case
executionid
and
pipelinename
.
Now let’s look at the second CloudWatch Event Rule which will be triggered if CodeBuild fails (step 10b):
232 CloudWatchEventRuleBuildFailed:
233 Type: AWS::Events::Rule
234 Properties:
235 EventPattern:
236 source:
237 - aws.codebuild
238 detail-type:
239 - 'CodeBuild Build State Change'
240 detail:
241 build-status:
242 - FAILED
243 project-name:
244 - !Sub ${AWS::StackName}-GetAzureDevOps-Repo
245 Targets:
246 -
247 Arn: !Sub ${LambdaCodeBuildFails.Arn}
248 Id: failtrigger
249 InputTransformer:
250 InputPathsMap: {"loglink":"$.detail.additional-information.logs.deep-link", "environment-variables":"$.detail.additional-information.environment.environment-variables", "exported-environment-variables":"$.detail.additional-information.exported-environment-variables"}
251 InputTemplate: "{\"loglink\": <loglink>, \"environment-variables\": <environment-variables>, \"exported-environment-variables\": <exported-environment-variables>}"Again, I want to draw your attention to the InputPathsMap and InputTemplate part.
Here we extract 3 variables:
-
loglink (single string value) → deeplink to the CloudWatch logs for CodeBuild execution
-
environment-variables (array of objects) → execution_id and pipelinename objects
-
exported-environment-variables (again array of objects) → jobId object
The InputTemplate creates a simple JSON file which will be later used by the Lambda function (step 11b).
CodeBuild
Most of the logic of this solution can be found in the CodeBuild project. The project will have 2 environment variables
pipelinename
and
executionid
(lines 127-131) and as seen before will be pre-filled by the Webhook event (step 7).
Now let’s get to the meat of the project, the BuildSpec part:
134 BuildSpec: !Sub |
135 version: 0.2
136 env:
137 exported-variables:
138 - jobid
139 phases:
140 pre_build:
141 commands:
142 - echo $pipelinename
143 - echo $executionid
144 - wait_period=0
145 - |
146 while true
147 do
148 jobdetail=$(aws codepipeline poll-for-jobs --action-type-id category="Source",owner="Custom",provider="AzureDevOpsRepo",version="1" --query-param PipelineName=$pipelinename --max-batch-size 1)
149 provider=$(echo $jobdetail | jq '.jobs[0].data.actionTypeId.provider' -r)
150 wait_period=$(($wait_period+10))
151 if [ $provider = "AzureDevOpsRepo" ];then
152 echo $jobdetail
153 break
154 fi
155 if [ $wait_period -gt 300 ];then
156 echo "Haven't found a pipeline job for 5 minutes, will stop pipeline."
157 exit 1
158 else
159 echo "No pipeline job found, will try again in 10 seconds"
160 sleep 10
161 fi
162 done
163 - jobid=$(echo $jobdetail | jq '.jobs[0].id' -r)
164 - echo $jobid
165 - ack=$(aws codepipeline acknowledge-job --job-id $(echo $jobdetail | jq '.jobs[0].id' -r) --nonce $(echo $jobdetail | jq '.jobs[0].nonce' -r))
166 - Branch=$(echo $jobdetail | jq '.jobs[0].data.actionConfiguration.configuration.Branch' -r)
167 - Organization=$(echo $jobdetail | jq '.jobs[0].data.actionConfiguration.configuration.Organization' -r)
168 - Repo=$(echo $jobdetail | jq '.jobs[0].data.actionConfiguration.configuration.Repo' -r)
169 - Project=$(echo $jobdetail | jq '.jobs[0].data.actionConfiguration.configuration.Project' -r)
170 - ObjectKey=$(echo $jobdetail | jq '.jobs[0].data.outputArtifacts[0].location.s3Location.objectKey' -r)
171 - BucketName=$(echo $jobdetail | jq '.jobs[0].data.outputArtifacts[0].location.s3Location.bucketName' -r)
172 - aws secretsmanager get-secret-value --secret-id ${SSHKey} --query 'SecretString' --output text | base64 --decode > ~/.ssh/id_rsa
173 - chmod 600 ~/.ssh/id_rsa
174 - ssh-keygen -F ssh.dev.azure.com || ssh-keyscan ssh.dev.azure.com >>~/.ssh/known_hosts
175 build:
176 commands:
177 - git clone "git@ssh.dev.azure.com:v3/$Organization/$Project/$Repo"
178 - cd $Repo
179 - git checkout $Branch
180 - zip -r output_file.zip *
181 - aws s3 cp output_file.zip s3://$BucketName/$ObjectKey
182 - aws codepipeline put-job-success-result --job-id $(echo $jobdetail | jq '.jobs[0].id' -r)
183 artifacts:
184 files:
185 - '**/*'
186 base-directory: '$Repo'First of all, we define a custom environment variable which will be filled with the
jobid
later on (lines 136-128). Defining a custom environment variable for the
jobid
will ensure that we have a value for the
jobid
in the CodeBuild response (which will later be received by the CloudWatch Event Rule in case of errors).
Polling CodePipeline for jobs usually needs more than one try to get a result, therefore we use a while loop and poll all 10 seconds (step 8).
As you can see on line 148 we only poll for jobs with the correct
PipelineName
(remember that we defined this property as query able).
If we don’t get a result within 5 minutes we will exit the CodeBuild execution with a non-zero exit code which will lead to 'FAILED' state and which will trigger the CloudWatch Event Rule for errors (lines 147-162).
Now we acknowledge the job and we ask the CodePipeline to provide more details on the job (lines 163-171, step 8):
-
Branch, Organization, Repo, Project → Azure DevOps properties
-
ObjectKey, BucketName → these two parameters are very essential for the next CodePipeline step
Before we can clone the repo we have to put the decoded base64 ssh key received from the Secrets Manager into the correct file in the CodeBuild container (step 9).
We change the access permissions on the created key file to 600 and add the Azure DevOps public keys to the known_hosts file. (lines 172-174)
Now the actual build process starts, and the repo is cloned using the copied SSH key for authentication. Before zipping all the repo content, the appropriate branch is checked out and the zipped artifact is then uploaded to the artifact store (step 10a).
Here we see again the two parameters
ObjectKey and BucketName
received earlier from the job details. The artifact has to use the value of
ObjectKey
as filepath/name and
BucketName
as S3 bucket name for the upload. It is very crucial to use the correct filepath/name because the next CodePipeline Step/Stage will try to download the artifact form the Artifact Bucket using these two parameters and will fail if you used wrong values during upload.
Last action of the CodeBuild project is to inform the CodePipeline of a successful execution of the job (line 182, step 11a).
Lambda Function
The Lambda function will only be used for error handling. The logic is pretty simple as you can see here:
338 def lambda_handler(event, context):
339 LOGGER.info(event)
340 try:
341 job_id = event['exported-environment-variables'][0]['value']
342 print(job_id)
343 execution_id = event['environment-variables'][0]['value']
344 print(execution_id)
345 pipelinename = event['environment-variables'][1]['value']
346 print(pipelinename)
347 loglink = event['loglink']
348 print(loglink)
349 if ( job_id != "" ) :
350 print("Found an job id")
351 codepipeline_failure(job_id, "CodeBuild process failed", loglink)
352 else :
353 print("Found NO job id")
354 codepipeline_stop(execution_id, "CodeBuild process failed", pipelinename)
355 except KeyError as err:
356 LOGGER.error("Could not retrieve CodePipeline Job ID!\n%s", err, pipelinename)
357 return FalseFirst we get all variable values which were provided by the CloudWatch Event Rule and then we only check if there is a value for
job_id
.
If there is a value we will trigger the codepipeline_failure function which then will inform CodePipeline of a failure result of this job (lines 312-323).
Whenever CodeBuild fails without getting a
job_id
before the error occurs the Lambda function will call the codepipeline_stop part. The
execution_id
and
pipelinename
is then used to stop and abandon the correct CodePipeline execution (lines 324-337).
Summary
I hope this post showed you how you can create your own CodePipeline sources and how the different parts of such a solution are playing together. This was my first time creating a custom CodePipeline source and I’m fascinated how powerful this is. You may include completely different sources into your CodePipelines, not limited to Repos at all. Wherever you have a solution which can trigger a Webhook and provide some input you are fine to use it as your own CodePipeline source.